Consulting
American Beauty Institute
I am a Data Engineering Consultant for American Beauty Institute, a cosmetology school that offers certification education for various beauty-related fields, building their data platform from scratch to support their rapidly growing business as they expand in multiple locations.
Links: GitHub | Documentation

At The Table
At The Table connects foster youth with educational resources. The executive director maintained multiple versions of a scorecard spreadsheet for partner organizations, a time-consuming process that took away from directly serving students. I developed a centralized web application that replaced the fragmented spreadsheet system with an intuitive interface accessible to non-technical audiences.
This web app serves not only the staff and students in At The Table, but also Fair Futures and students in CUNY's Foster Youth College Success Initiative, among many other partner non-profits and foster care advocacy organizations.

Projects
koffee
koffee is a lightweight CLI tool that translates a given video file to the target language, outputting a translated subtitle file.
It was developed for myself and friends at a Discord community where there are many fans of K-pop and Anime, serving dozens of users weekly.
Links: GitHub | Documentation

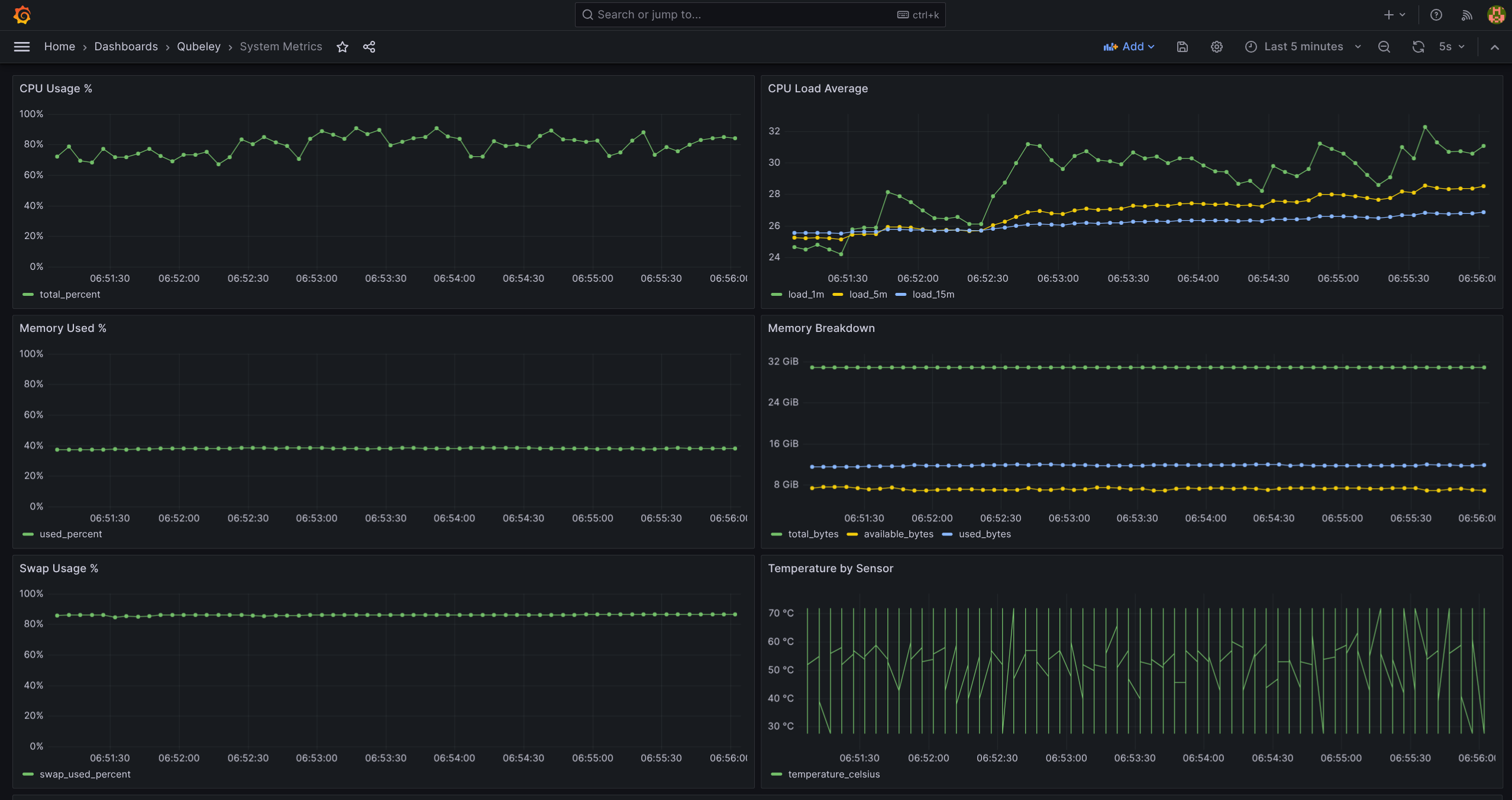
Qubeley
Qubeley is a real-time systems metrics pipeline that continuously collects CPU, memory, temperature, and log data from a host machine and stores it in a queryable time-series database, written purely in Go.
Unlike built-in system monitors that only show the current moment, Qubeley retains historical data so you can query, visualise, and analyse trends over time. It is designed to be self-hosted, lightweight, and easy to run locally with no external dependencies beyond Docker and Go.
Links: GitHub
RAWG Video Game Data Pipeline
I built this data pipeline as I was getting into the Data Engineering space to playtest various tools I found interesting, but to also pique my curiosity on video game trends. It sources data from RAWG's public API and is ultimately fed into a Streamlit web app to visualize the trends.
Links: GitHub

Open Source Contributions
Dagster
I resolved a long-standing issue where dynamically mapped Dagster steps failed to load ML models from S3, originally reported by a user who noticed Dagster's dynamic step names contain square brackets which S3 accepts, but Spark interprets as glob wildcards, making files unreadable despite being present in storage.
My fix finally automated path sanitization for dynamic mapping, unblocking anyone persisting ML models or serialized objects to S3 and removing the need for users to build their own workarounds.
Links: Pull Request | Issue

LlamaIndex
I added support for pathlib objects to one of the most commonly used data loading
modules in LlamaIndex, the SimpleDirectoryReader, after I noticed it only
accepted string paths.
Links: Pull Request | Issue
